![]()
www.heteroclinic.net
|
XXI. The Procedure to Convert NFA to REX 5 201511
The accepter of XX will not accept an exact record. So after we accept a record, we can go a further step into micro-management or attend to more details. In computing, we usually use cache that stores data so that data can be served faster. In our accepter, the fastness is not the issue in discussion but to simplify the structure of the accepter. When we get a matching string or data stream etc, we can strip off the leading and trailing quote, then use regex to grep quote that does not appear in pair. If it is, we reject this string or partial stream. If not, then we accept it. Moreover, we will replace paired quotes with one quote if they exist. Thus, we will get a record more matching the RFC specification. We thus process our stream with a hierarchical structure. The higher command, administration or logical unit will not enter too much into the micro-management of the lower command, administration or logical units, thus save their container size or logic.
The root of cache is from 'hiding place' used by French Canadian trappers in their slang -- http://dictionary.reference.com. A professor once explained more about it. The hunters in the mountainous area of north America normally built some cabins. When they hunted some animals, they will bring them to the shelter at sight to process/skin the trophies. After a given amount hides accumulated or the hunting season is over, the hunter can take the stash and head for the market which I believe in ancient time or even today, traveling in such an area may simply take days for a couple of miles even without being lost. So the argument is that it is not cost-effective that the hunter just brings one hide to market at once. Also, in practice, if we focus on one type of work thus the improvement of proficiency will make the work more efficient. The hunter may just focus on hunting during the hunting season or even may keep hunting and outsource the marketing to a friend or local dealer. Metaphorically, we may use one thread to churn out the rough records and put them to a queue, another thread may churn out the record matching the RFC and strip them of the RFC overhead. The process of the fields in the records just has its similarity as shown in our program example.
|
||||||||||||||||||||||
|
XXII. The Procedure to Convert NFA to REX 6 201511
In this section, we are going to apply the procedure to our accepter. So we will first apply (3.3) $$\ref{equ_3_3}$$, which is
You may achieve higher productivity by use Microsoft Excel or Libre Office electronic forms software than using html with a text editor.
further algebraic replacement
|
||||||||||||||||||||||
|
XXIII. The Procedure to Convert NFA to REX 7 201511
We simplify the second table at section(XXII), we get the following table.
Now, we reduce the accepter with only two states $$q_0$$ and $$q_2$$ as the following graph. 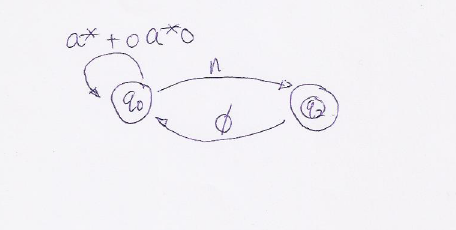 |
||||||||||||||||||||||
|
XXIV. The Procedure to Convert NFA to REX 8 201511
At this step, we can apply (3.2) $$\ref{equ_3_2}$$, which is
Here we have $$i = 0, j=2$$,
Note during the second step $$\Phi ^ *$$ is a star closure, it should not be considered as a broken travel plan. So the final regex would be
As the book mentioned this procedure is 'mechanical but tedious'. It is required for a further discovery of more important results. But we found it is high algebraic friendly for programming. Can we feed a graph to such a procedure?
A seasoned shell script-or may also question such a regex can be figured out in minutes. It is true. But still can we figure out a way to convert arbitrary (not very complex) accepter to regex? So far, it looks programmatic-ally feasible. Also at the early age of designing transistors or logical gates, it does not suffice.
So mentioned logical gates, I would mention a use case of the management process of an senior undergraduate EE course I participated. The final lab project (labs as a whole counted about 25 to 30% of the course to get a pass), not vital but important, is a breadboard design of logical gates of a two digits (not two bits) calculator something. You can not blame the students being lazy or not qualified though the average is not high, some of them struggled to do graduate at some good universities or get a job from some well-known employers. It was the end of spring, too many finals were zipped into a short week or two, you can imagine the final years of EECS. So the students beg the leniency to submit the final lab after the spring vacation and granted. So at the due day after the spring vacation, for some it is spring vocation to do jobs in restaurants or factories for allowance of the next term, it looks like barely anybody remembered what they learned just two weeks ago. Two teams rushed some untested breadboards and others just turn in blank. Finally there was a leniency from the lab director stayed very late in the night till the some time of the next day help the students resume from such a context switch. That is what I am saying for the cache story.
It is a straightforward regex, but why we spent too many tests to acquire the result. So I would have to mention the issue of wild card '.' -- Pattern in Java programming language, we don't know what it is, can we enumerate all the elements matching '.', so the alphabet is a finite set, all keyboard characters, all Unicode characters, so we can calculate the subsets of it like we annotate as a,n,o. If you read the test cases I wrote, probably you can find the confusion and still it is not quite cleared.
|